Alejandro Villegas Sánchez.
Alvaro Serrano Íñigo.
Talía Lucero Azabache García.
Blog: https://ayudagestioninfo.blogspot.com/
INTRODUCCIÓN:
Actualmente Google es el buscador más usado y conocido a nivel mundial. Además de este existen muchos más tipos de buscadores en Internet, pero hoy nos centraremos en este. En uno de nuestros anteriores artículos; describimos más a fondo cómo funcionan estos buscadores. Sin embargo, hoy trataremos la recuperación de la información.
La información puede recuperarse a través de distintas herramientas como: bases de datos, Internet, mapas, ontologías. Además, saber hacer un buen uso de estas contribuye a recuperar una buena calidad de la información.
 https://www.ecured.cu/images/5/5f/RI.jpg |
-Como se almacena la información.
El lugar donde se almacena la información es esencial para la recuperación de esta. Imagínense que en un supuesto caso, Google tuviese que almacenar todos sus datos en discos duros, sería prácticamente imposible, ¿cierto? . Por ello, utilizan unas instalaciones llamadas centros de datos.
Un centro de datos, es un espacio de servidores en el que se gestiona, se almacena y se protege la información. Son usados generalmente por compañías encargadas de manejar y procesar grandes cantidades de datos desempeñando un papel importante en el ámbito de servicios electrónicos. Estas instalaciones son la base tecnológica para la realizar diferentes transacciones o distribuir contenido, siendo así fundamentales para los bancos o compañías de Internet.

Uno de los mayores centros de datos se localiza en España, concretamente en Madrid. Este cuenta con 90.000 servidores, además de 60.000 circuitos interconectados y 48.000 km de cable, dando servicio a 250 clientes como; Ferrovial, Overon, AMC, etc.
En los centros de datos, los servidores se encuentran en grandes salas, encerrados en cajas, las cuales consiguen mantener los equipos a temperatura óptima. También, está presentes las salas de interconexión, en la que a través de cableado los operadores, con Telefónica como principal proveedor, se conectan con los clientes.

-Seguridad de los centros de datos.
La seguridad en estas instalaciones es esencial debido a la gran cantidad de información que se almacena en ellas. Generalmente, el punto de entrada requiere una tarjeta de acceso, para vigilar la entrada y salida de personal y material. El acceso a las salas de los servidores es aún más restringido, y para entrar a ellas se emplea un lector de huellas dactilares. Además, todo está vigilado con cámaras de circuito cerrado.

Google emplea una seguridad física bastante parecida en sus instalaciones. Sus instalaciones están totalmente valladas y vigiladas 24h al día. En el interior identifican a los usuarios que quieran entrar mediante análisis biométricos.
En cuanto a la protección de datos, es un apartado que Google se toma muy en serio. Los datos se guardan en diferentes localizaciones para garantizar su disponibilidad. Además de la seguridad física se utilizan algoritmos de encriptación, los datos no son guardados en texto, sino cifrados.
En 2013 Google tenía 13 centros de datos, en los que había aproximadamente 900.000 servidores. Estos fueron montados a medida por Google y funcionan bajo la distribución de Linux personalizada por Google.
Bibliografía:
https://www.elperiodico.com/es/tecnologia/20121017/donde-se-guardan-todos-los-datos-degoogle-2228160
https://www.elboletin.com/noticia/149793/tecnologia/en-el-corazon-de-internet:-como-funcio na-un-data-center.html
http://www.mariapinto.es/e-coms/busqueda-y-recuperacion-de-informacion/
https://es.wikipedia.org/wiki/Centros_de_datos_de_Google
TÉCNICAS DE RECUPERACIÓN Y ALMACENAMIENTO DE LA INFORMACIÓN.
A todos nos ha pasado alguna vez como mínimo, si no más, de alguna foto, vídeo, archivo... que queramos volver a ver, reproducir o simplemente disfrutar de ello, y no hay manera de que aparezca.
Para ello, pues existen diversas formas o técnicas de búsqueda para estos elementos desaparecidos.

- Retroalimentación por relevancia: Consiste en mantener mantener el mayor número de documentos estableciendo distintas estrategias de búsqueda. Lo que viene siendo en refinar la búsqueda del/los elementos, añadiendo así algún filtro en la búsqueda o algún parámetro adicional más específico. De esta forma, añadiendo parámetros o filtros más específicos para la búsqueda, se dan dos ocasiones de almacenamiento y búsqueda:
- Silencio documental: Son aquellos documentos almacenados en la base de datos pero que no han sido recuperados, debido a que la estrategia de búsqueda ha sido demasiada específica.
- Ruido documental: Son aquellos documentos recuperados por el sistema pero que no son relevantes en la búsqueda. Este caso se suele dar cuando la estrategia de búsqueda es demasiado genérica.
- Lógica difusa: Consultar con frases sencillas, de forma que al realizar la búsqueda, elimina artículos, puntuación, palabras comunes, etc., dejando así solo las palabras relevantes. Estos dos métodos eran bastante simples además de que a cualquier usuario se le podría haber ocurrido intentar, por lo que pasamos a uno un pelín más complicado.
- Cluster: Esta técnica es un modelo que identifica las frecuencias de los términos de búsqueda en la información recuperados. Se dan unos valores que actúan como agentes para organizar la información por orden de importancia, mediante algoritmos, por lo que la técnica del clustering también sirve para ordenar información. (Lo de los algoritmos lo vemos luego). Una muestra de cómo funciona la técnica del clustering:
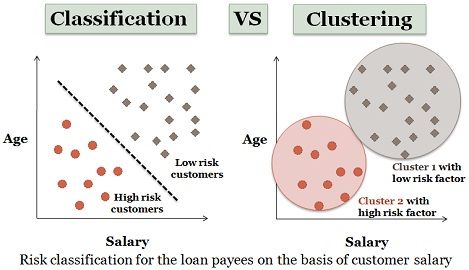
Esto empieza con la llamada hipótesis cluster, la cual dictamina qué documentos relacionados mediante esta técnica tienden a ser más relevantes para las mismas búsquedas.
En un fichero en el cual se han realizado estas técnicas, los documentos que pertenecen a un mismo cluster se almacenan en unos "localizadores adyacentes" y de esta manera un único acceso permite la recuperación de todos los documentos de un mismo cluster.
Por tanto en la recuperación de los parámetros de la búsqueda no se comparan con todos los documentos, sino que se comparan con el representante de cada una de las clases de la base de datos.
Sin embargo, como buena técnica, requiere obviamente de un buen algoritmo, de entre los cuales hablaremos del Algoritmo K-Means (K-medias en español).

El algoritmo k-means, es un método de agrupamiento, que tiene como objetivo, la separación de un conjunto de "n " observaciones en "m " grupos donde cada observación pertenece al grupo cuyo valor medio es más cercan.
El algoritmo estándar de este utiliza una técnica de refinamiento iterativo. También es conocido como el algoritmo de Lloyd, mayormente en la comunidad informática.
(Antes de nada, como vamos a ver, el concepto centroide se refiere a un punto el cual expresa el centro de una figura geométrica).
Con un conjunto de "centroides " el algoritmo realiza dos pasos:
- Paso de asignación: Asigna a cada observación al grupo con la media más cercana.
- Paso de actualización: Calcula los nuevos centroides como el centroide de las observaciones del grupo.

https://wikimedia.org/api/rest_v1/media/math/render/svg/cdd16cba1836f523f4f11d149ac3826598506c5e
Finalmente, el algoritmo se considera que ha acabado una vez las asignaciones de los centroides ya no cambian.
Claro, este algoritmo tiene unas específicas especificaciones valga la redundancia:
Se suele usar para grandes conjuntos de datos, por lo que ha sido ampliamente usado en áreas como segmentación de mercados, geoestadística o astronomía entre otros.
Como especificaciones más concretas, encontramos:
-Código fuente escrito en C++, Python with scipy
-Software de forma libre: Apache Mahout, ELKI, SciPy o CMU's GraphLab Clustering Library
-Algunas variaciones como Fuzzy C-Means Clustering, Algoritmo esperanza-maximización...
Bibliografía:
https://es.wikipedia.org/wiki/K-medias
http://www.mariapinto.es/e-coms/busqueda-y-recuperacion-de-informacion/
http://galeon.com/clustering/tecnicas.htm
http://recuperaeinforma.blogspot.com/2011/09/tecnicas-de-recuperacion-de-informacion.html
LOS BUSCADORES
Los buscadores son herramientas que permiten facilitarnos el ubicar y recuperar información guardada en internet sobre un tema en concreto. Poseen similitudes en su funcionamiento con las bases de datos. Guardan páginas con determinadas características (metadatos) y después, al usar palabras claves, muestra un listado con las más destacadas, relacionadas con el tema consultado. Entre ellas destacan: Google, Yahoo!, Bing, Alexa... Sin embargo, se distinguen en que proporcionan información de carácter general, es decir, sin una gran profundización.

- Los índices de búsqueda, fueron el primer tipo en crearse. El primero en originarse fue Yahoo. Estos índices son originados por un grupo de personas que agrupan la información en temas con subcategorías.
- Los motores de búsqueda o buscadores, son los encargados de realizar la búsqueda de las webs a través de un programa llamado araña, creando una base de datos que relaciona la dirección de la página web con las 100 primeras palabras que aparece en esta. Podemos encontrar a: Google, Bing...

- Los metabuscadores, son buscadores que, para ofrecernos una información, utilizan bases de datos de otros buscadores. Por ejemplo, Metracrawler, Zapmeta, Copernic...
Es una herramienta de búsqueda que nos permite tener al alcance una gran cantidad y variedad de información, páginas web, imágenes, vídeos...
Es uno de los motores de búsqueda más importante y utilizado en la actualidad.
Entre sus ventajas destacan: su formato simple y fácil de utilizar, la rapidez de su ejecución y su posesión de diversas herramientas beneficiosas a la hora de realizar las búsquedas.
Para buscar y seleccionar información a través de los buscadores, es el principal motivo por el cual se necesitan adquirir habilidades, conocimientos y una mayor destreza a la hora de aprender a darles uso.
Para acceder tenemos que ejecutar un explorador y escribir la URL: www.google.es.

La página principal contiene diferentes campos:
- Vínculos superiores: permiten selecciones diferente tipos de herramientas que nos ofrece.
- Configuración de búsqueda: en el que podemos elegir preferencias, como por ejemplo, el idioma o número de páginas.
- Cuadro de búsqueda: espacio en el que se coloca las palabras claves.
- Búsqueda avanzada: nos permite concretizar más en nuestras búsquedas.
- Herramientas de idioma.
- Barras de estadísticas: nos muestra la cantidad de resultados obtenidos y el tiempo que se ha tardado en realizar la búsqueda.
- Título de la página y el texto, se trata de un breve resumen.
- Páginas similares: páginas similares obtenidas en la búsqueda.
En Google se pueden realizar mediante búsquedas: simples y avanzada.
❖ Búsqueda simple
Se puede realizar mediante una palabra o varias palabras. Google nos muestra automáticamente
una lista de palabras que comienzan con esas letras.
Para reducir nuestra búsqueda solo tenemos que añadir más letras en nuestra búsqueda.
❖ Búsqueda avanzada
Nos permiten limitar los resultados a obtener según nuestras preferencias. Por ejemplo:
resultados, número de páginas, idioma, fecha, región, presencia, dominio, derechos de uso,
safe search y formato de archivo.
❖ Otras búsquedas: imágenes, videos, libros y google académico.
Bibliografía
https://www.uv.es/avirtual/internet/t_4_1.htm http://ci2.ual.es/como-funcionan-buscadores-como-google-y-las-bases-de-datos/
http://recursostic.educacion.es/observatorio/web/es/internet/recursos-online/1004-busqueda s-avanzadas-en-google
https://computurismodm.wordpress.com/2016/09/17/los-buscadores/
https://www.aula21.net/tallerwq/buscadores/buscador1.htm
No hay comentarios:
Publicar un comentario